When getting swisstopo altitude profiles the response time is in general quite good but just sometimes I ran into timeouts, be it due to my bad connection or too many requests to the server. To amend I added this decorator that you can get as the most up-to-date version from my GitHub gists to the original swisstopo function (or other functions that might run into some form of timeout)
defexponential_retry(max_retries, delay):"""Retry a request with exponentially increasing (slightly random) time in between tries""""""Usage before def of another function via @exponential_retry(5, 1) """defdecorator_exponential_retry(func):import functools@functools.wraps(func)defwrapper_exponential_retry_decorator(*args, **kwargs):import random retries =0while retries <= max_retries:try:return func(*args, **kwargs)exceptExceptionas e:print(f"Attempt {retries +1} failed: {e}") retries +=1 sleeptime = (delay *2** retries + random.uniform(0, 1))print(f"Retrying in {sleeptime:.2f} seconds...") time.sleep(sleeptime)raiseException("Maximum amount of retries reached, too many timeouts/errors.")return wrapper_exponential_retry_decoratorreturn decorator_exponential_retry@exponential_retry(5, 1)defget_swisstopo_elevation_profile(...): .# source code of get_swisstopo_elevation_profile...
TL;DR; The below code can be added as a script to your page to implement a touchdown event detection and directly attach it to a “menu” element
asyncfunctionswipedetect(el, callback, threshold=50, minimumTime=150, allowedTime=2000){var touchsurface = el, swipedir, startX, startY, distX, distY, threshold = threshold, //required min distance traveled to be considered swipe in X// restraintX = restraintX, // maximum distance allowed at the same time in perpendicular direction in X// thresholdY = thresholdY, //required min distance traveled to be considered swipe in Y// restraintY = restraintY, // maximum distance allowed at the same time in perpendicular direction in Y minimumTime = minimumTime, // maximum time allowed to travel that distance allowedTime = allowedTime, // maximum time allowed to travel that distance elapsedTime, startTime, handleswipe = callback ||function(swipedir){} touchsurface.addEventListener('touchstart', function(e){var touchobj = e.changedTouches[0] swipedir ='none' dist =0 startX = touchobj.pageX startY = touchobj.pageY startTime =newDate().getTime() // record time when finger first makes contact with surface// e.preventDefault() }, false) touchsurface.addEventListener('touchmove', function(e){ e.preventDefault() // prevent scrolling when inside DIV }, false) touchsurface.addEventListener('touchend', function(e){var touchobj = e.changedTouches[0] distX = touchobj.pageX - startX; // get horizontal dist traveled by finger while in contact with surface distY = touchobj.pageY - startY; // get vertical dist traveled by finger while in contact with surface dist = distY * distY + distX * distX; dist = Math.sqrt(dist); elapsedTime =newDate().getTime() - startTime; // get time elapsed// calculate the angle of the movement angle = (Math.atan2(distY, distX) / Math.PI*180)// convert angle to a sector of the movement// offsetting it by 45 degreees to get the movement easier.// and ensuring its positive sector = (angle +45+360) %360; sector = Math.floor(sector/90);if (elapsedTime >= minimumTime && elapsedTime <= allowedTime && dist >= threshold){ // first condition for a swipe metswitch (sector) {case0: swipedir ="right"; break;case1: swipedir ="up"; break;case2: swipedir ="left"; break;case3: swipedir ="down"; break; } }handleswipe(swipedir)if (dist >= threshold) { e.preventDefault() } }, false)}asyncfunctionswipe_enable(elementid='menu', table={'right':'a', 'up':'w', 'left':'d', 'down':'s', 'none':null}) {var el = document.getElementById(elementid);if (el) {swipedetect(el, asyncfunction(swipedir){//swipedir contains either "none", "left", "right", "top", or "down"let key = table[swipedir]; document.dispatchEvent(newKeyboardEvent('keypress', {'key': key})); }) }}
Handling a touchdown event via vanilla JS is nothing new, and I also took the initial implementation from a website I cannot find anymore. The structure was similar to this gist and the related discussion, as in initially I simply added a touchdown but the detection of right/left/up/down was patchy until I also added the direction sector. Additionally, I did not want to attach it all the time to each element etc. but instead added another function that handles the attaching.
Now I can simply have the above in a js-lib file and source it on our data visualisation page, then call swipe_enable() in the doc.ready function and be certain that swiping is handled on the corresponding element (with selects in this case). This makes usage of the page far easier on mobile devices; highly relevant if you are in the field like in CLOUDLAB and your phone is the only thing available due to the windy/rainy/snowy weather.
Get the census data (and more) from the Basler Atlas that are updated by the Statistisches Amt Basel. The up-to-date version can be found on my GitHub Gists. Don’t forget to add the data source, i.e. the Stat. Amt Basel when you use their data. – it is being added automatically to the “meta” part in the datacontainer (in addition to the URL, the name and short name of the dataset).
import datetimeheaders = {'User-Agent': 'Mozilla/5.0'}defdata2csv(data,outpath='./',prefix='',suffix='',filesep='_',datasep=',',ext='.csv',quiet=True, ):import osifisinstance(data, dict) and'data'notin data.keys(): of = []for key in data.keys(): _of = data2csv(data[key],outpath=outpath,prefix=prefix,filesep=filesep,datasep=datasep,ext=ext,quiet=quiet, )ifisinstance(_of, list): of += _ofelse: of.append(_of)return of outpath = os.path.expanduser(outpath) filename = filesep.join([prefix, data['meta']['theme'], data['meta']['subtheme'], _nivgeo2nicename(data['meta']['nivgeo']), suffix, ]) filename = filename.lstrip(filesep).rstrip(filesep) + ext os.makedirs(outpath, exist_ok=True)ifnot quiet:print('Saving as', outpath+filename)withopen(outpath+filename, 'w') as file_obj: file_obj.writelines(datasep.join(data['header']) +'\n') datalines = [datasep.join(map(lambdax: str(x), line))for line in data['data']] file_obj.writelines('\n'.join(datalines) +'\n')return outpath+filenamedef_get_topic_url(): url ='https://www.basleratlas.ch/GC_listIndics.php?lang=de'return urldef_get_data_url():# used to be the first url at around 2018# "https://www.basleratlas.ch/GC_ronds.php?lang=de&js=1&indic=bevstruk.alter0&nivgeo=wge&ts=1&serie=2015" url ='https://www.basleratlas.ch/GC_ronds.php' url ='https://www.basleratlas.ch/GC_indic.php'return urldef_get_references_url():# e.g. https://www.basleratlas.ch/GC_refdata.php?nivgeo=wbl&extent=extent1&lang=de url ='https://www.basleratlas.ch/GC_refdata.php'return urldefget_ref_data(nivgeo, slimmed=True):import requests payload = {'nivgeo': nivgeo,'lang': 'de', 'extent': 'extent1'} refs = requests.get(_get_references_url(),params=payload,headers=headers) refdata = refs.json()['content']['territories']# contains the actual numbering in the main geographical administrative# dataset that it can be linked againstif slimmed:return refdata['libgeo'], refdata['codgeo']else:return refdatadef_replace_error_value(value, error_value, replace_value):return replace_value if value <= error_value else valuedefget_basler_atlas_data(nivgeo,theme,subtheme,year,quiet=True,error_value=-9999,replace_value=0,empty_value='', ):import requestsfrom requests.exceptions import JSONDecodeError payload = _params2payload(nivgeo, theme, subtheme, year=year) response = requests.get(_get_data_url(),params=payload,headers=headers)if response.ok:try: data = response.json()['content']['distribution']except JSONDecodeError:print(f'issues with {response.url} and the payload {payload}')returnNone, Noneifnot quiet:print(f'Got data from {response.url}, transforming ...') values = data['values']if'sortIndices'in data:# reported values are to be sorted, usual case? indices = data['sortIndices']else:# reported values are sorted already, usual case for Bezirk? indices =range(len(values))ifisinstance(values, dict): keys =list(values.keys()) indices =range(len(values[keys[0]])) values = [[_replace_error_value(values[key][i], error_value, replace_value, )for key in keys]for i insorted(indices) ] data = valuesreturn keys, dataelse: data = [str(_replace_error_value(values[i], error_value, replace_value, ) )for i insorted(indices)]returnNone, dataelse:ifnot quiet:print(f'Request for {payload} failed')returnNone, Nonedef_nivgeo2map(nivgeo): lookuptable = {'block': 'map5','wbl': 'map5','bezirk': 'map6','wbe': 'map6','viertel': 'map2','wvi': 'map2','gemeinde': 'map3','wge': 'map3',# 'wahlkreis': 'map7',# 'pwk': 'map7', }return lookuptable[nivgeo]def_get_nivgeos():return'wbe', 'wvi', 'wge', 'wbl'# , 'pwk'def_nicename2nivgeo(nivgeo=None): nicenames = _nivgeo2nicename(nivgeo=nivgeo)if nivgeo isNone:return {v: k for k, v in nicenames.items()}else:return {nicenames: nivgeo}def_nivgeo2nicename(nivgeo=None): names = {'wbe': 'bezirk','wvi': 'viertel','wge': 'gemeinde','wbl': 'block',# 'pwk': 'wahlkreis', }if nivgeo isNone:return nameselse:return names[nivgeo]def_params2payload(nivgeo,theme,subtheme,year=None): payload = {'lang': 'de','dataset': theme,'indic': subtheme,'view': _nivgeo2map(nivgeo), }if year isnotNone: payload['filters'] ='jahr='+str(year)return payloaddefget_basler_atlas(start_year=1998,end_year=datetime.date.today().year,# population has different ages,# men m , women w and a grand totalthemes={'bevstruk': ['alter0','alter20','alter65','w','m','gesbev'],'bevheim': ['anteil_ch','anteil_bs','anteil_al','anteil_bsanch',# "gesbev" has been replaced by'gesbev_f', ],'bau_lwg': ['anzahl_lwg', ], },geographical_levels='all',error_value=-9999,replace_value=0,testing=False,quiet=True, ): _nicenames = _nicename2nivgeo()if geographical_levels =='all': nivgeos = _get_nivgeos()else:ifisinstance(geographical_levels, str): geographical_levels = [geographical_levels] _nivgeos = _get_nivgeos() nivgeos = [i if i in _nivgeos else _nicenames[i]for i in geographical_levels]assertall([i in _nivgeos or i in _nicenamesfor i in nivgeos])# the defaults that we know of - there is wahlbezirke too on the# atlas but we don't particularly care about that one... data = {}# mapping of information from topic url to meta information entries info2meta = {'url': 'c_url_indicateur','name': 'c_lib_indicateur','short_name': 'c_lib_indicateur_court','unit': 'c_unite','source': 'c_source','description': 'c_desc_indicateur', }for nivgeo in nivgeos: refname, refnumber = get_ref_data(nivgeo) refdata = [[_refname, _refnumber]for _refname, _refnumber inzip(refname, refnumber)]# ids of the nivgeo is in refdata['codgeo']# names of the nivgeo is in refdata['libgeo'] nicename = _nivgeo2nicename(nivgeo)for theme in themes:ifnot quiet:print(f'Working on {theme} for {_nivgeo2nicename(nivgeo)}')for subtheme in themes[theme]:ifnot quiet:print(f'Working on {theme}.{subtheme} for ',f'{_nivgeo2nicename(nivgeo)}')# force a copy of refdata otherwise we keep updating the old list of lists. container = {'data': [i.copy() for i in refdata],'meta': {'theme': theme,'nivgeo': nivgeo,'subtheme': subtheme,'theme': theme, },'header': ['referencename', 'referencenumber'], } topicinfo = get_basler_atlas_topics(theme=theme,subtheme=subtheme,fullinfo=True)for key, value in info2meta.items(): container['meta'][key] = topicinfo[theme][subtheme][value]# values will be nested, adjust header line with extrafor year inrange(start_year, end_year+1):ifnot quiet:print(f'Getting data for {year} for {theme}',f'{subtheme} for {_nivgeo2nicename(nivgeo)}') keys, thisdata = get_basler_atlas_data(nivgeo, theme, subtheme, year,quiet=quiet, )if thisdata isNone:ifnot quiet:print(f'Failure to get data for {year} for {theme}',f'{subtheme} for {_nivgeo2nicename(nivgeo)}') thisdata = [''] *len(container['data'])if keys isNone: container['header'] += [f'{year}']else: container['header'] += [f'{year}_{key}'for key in keys]for i, value inenumerate(thisdata):ifnotisinstance(value, list): value = [value] container['data'][i] += valueif testing:break# year data[nicename+'_'+theme+'_'+subtheme] = containerif testing:break# specific themeif testing:break# themeif testing:break# nivgeoreturn datadefget_basler_atlas_topics(theme=None,subtheme=None,fullinfo=False):import requestsif subtheme isnotNoneandisinstance(subtheme, str): subtheme = [subtheme] payload = {"tree": "A01", 'lang': 'de'}if theme isnotNone: payload['theme'] = theme response = requests.get(_get_topic_url(),params=payload,headers=headers) topiclist = response.json()['content']['indics'] data = {}for topicinfo in topiclist: maintopic, subtopic = (topicinfo['c_id_dataset'], topicinfo['c_id_indicateur'])if maintopic notin data:if fullinfo: data[maintopic] = {}else: data[maintopic] = []if subtheme isnotNoneand subtopic notin subtheme:continueif fullinfo: data[maintopic][subtopic] = topicinfoelse: data[maintopic] += [subtopic]return dataif__name__=='__main__':print(""" Some example usages: # get some information for the population for the years 200 to 2003 data = get_basler_atlas(end_year=2003, start_year=2000, themes={'bevheim': ['anteil_ch','anteil_bs', ]}, geographical_levels='wvi', quiet=True) # just get everything that is a predefined topic: themes={'bevstruk': ['alter0', 'alter20', 'alter65', 'w', 'm', 'gesbev'], 'bevheim': ['anteil_ch', 'anteil_bs', 'anteil_al', 'anteil_bsanch', # "gesbev" has been replaced by 'gesbev_f', ], 'bau_lwg': ['anzahl_lwg', ], } # limit just by years data = get_basler_atlas(themes=themes, start_year=2000, end_year=2010) # also save the data to csv files (by theme and subtheme) data2csv(data) # get some information regarding the available topics themes = get_basler_atlas_topics()""")
In the years of 2014 to 2020 or so I was teaching “An introduction to Geoinformatics” at the University of Basel. As a starter, students were supposed to load data of the administrative units of Basel in the form of shapefiles into a GIS (ArcMap or QGIS, I gave support in both) and connect these with population data (age groups or similar). These data can be downloaded from the Statistisches Amt Basel, usually in the form of Excel sheets – which is doable for a GIS but not great to be used: Sometimes I even struggled with getting the right separator in the excel sheet to be automatically recognised for the later import (which is just one reason why I prefer QGIS). However, the updated numbers were sometimes published later than when I’d like to use them – even though the Basler Atlas already had them. So I went to work to scrape the data directly from this source, because I did not want to manually download the data each and every semester again and for several dataset individually. We can do better than that.
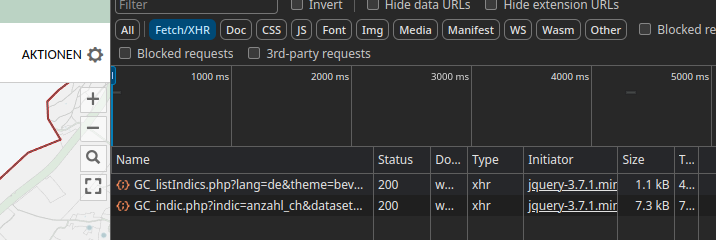
In the back, the Basler Atlas uses geoclip, a product from a French company (you also see their logo when opening the Atlas). Relevant for me was that with the browser inspect feature you can get the requests being made in the back and see where the data are coming from (you can of course also click on the request to see the direct answer)
As you can see there is a listIndics and a indic API endpoint. ListIndics gives an overview of datasets, indic gives the data of the “indices”. Both require some specific payload to work, the most important being {‘lang’: ‘de’}. There is however a third endpoint that gives the crucial reference information, namely the name/id of the administrative feature at GC_refdata.php. Initially, I only used the indic endpoint to collect the data directly and the ref to get the reference frame. Combining requests to both, the data can be collected automatically, either to update or for the first time and come back in dict, including a headerline and meta information for the later export (also included above). Now you can get your up-to-date data from the Basler Atlas as well and have a better time using it for temporal analysis by running the above code and then calling this or something like this
data = get_basler_atlas(geographical_levels='block',themes={'bevstruk': ['alter0','alter20','alter65','w','m','gesbev'], },quiet=True)
This gives you the population data on the block level of the years from 1998 until today (2024 as of this writing). Calling the below saves the data to your home directory, namely 6 CSV files.
data2csv(data, outpath='~/')
Today I extended the code above to also get the available topics (i.e. the categories). Which allows us to discover topics or download data that would require some time to find otherwise.
geolevel ='block'for key, values in topics.items():if key !='bevstruk':continue data = get_basler_atlas(themes={key: values},quiet=True,geographical_levels=geolevel) of = data2csv(data, outpath='~/')break
As always, I hope this helps someone to discover data or save some time for themselves. And maybe at some point, I’ll find the time to document everything a bit better. Don’t forget to add the data source, i.e. the Stat. Amt Basel when you use their data.
Update/Fix
As I noticed today, there was some issue with the previous version of this script, namely a “deepcopy” issue that led to the fact, that the datacontainer had data from all connected subthemes when more than one was requested. Ups. But it should be fine now, the gist on top is updated and some usage information is added as well. 🙂
Extract the single frames of a GIF to repurpose them (for example to create a video) with the below code. As always, the most up-to-date version can be found in the GitHub gist
def gif2imgs(file, save=False, outpath='same', outfilename='same', ):""" Extract image array from a GIF file. Based on PIL, frames of a GIF file are extracted to a numpy array. If more than one frame is present in the GIF, a list of numpy arrays is returned. It is possible to save the images directy, by defaultin the same path astheGIFandthesamebasename. Parameters---------- file : str The GIF file containing one or more image frames. save : bool, optional Whether to save the image frames directy. The default is False, i.e. the functionreturnsalistoftheimageframesasseperatenumpyarraysoutpath : str, optionalWheretosavetheextractedimageframes.Thedefaultis 'same', i.e. samefolderoutfilename : str, optionalHowtonametheextractedimageasfiles.Thedefaultis 'same', i.e. takingthebasenameandadding_frameXtoit. Ifastringispassed, thesamesuffixisaddedbutthebasenameistakenasthepassedinstring.Returns -------listofframesortwolists (offilenamesofextractedimageandimages)TheextractedframesfromtheGIFandifsavingwasturnedonalsothefilenamesofwrittenoutframes. """import PIL import numpyas np import os import matplotlib.image as img pilIm = PIL.Image.open(file) pilIm.seek(0) # Read all images inside images = [] try: while True: # Get imageas numpy array tmp = pilIm.convert() # Make without palette a = np.asarray(tmp) if len(a.shape) == 0: continue # Store, and next images.append(a) pilIm.seek(pilIm.tell()+1) except EOFError: pass if save: if outpath == 'same': outpath = os.path.dirname(file) + os.sep if outfilename == 'same': outfilename = os.path.basename(file) outfiles = [] for frameno, frame in enumerate(images): _ = outpath+outfilename.rstrip('.gif') + f'_frame{frameno}.png' img.imsave(_, frame, vmin=0, vmax=255) outfiles.append(_) return outfiles, images else: return imagesif __name__ == '__main__': import requests import matplotlib.pyplot as plt fileurl = 'https://gifdb.com/images/high/jumping-cat-typing-on-keyboard-2b15r60jnh8hn5sv.gif' response = requests.get(fileurl) filename = './example.gif' with open(filename, 'wb') as fo: fo.write(response.content) frames = gif2imgs(filename) plt.imshow(frames[0])
Recently I wanted to make a video for a talk. And that is where the trouble started.
Initially, I thought to place a video and GIF side by side. However, getting a synchronous playback was tricky because there are few to no control options for GIFs in most presentation software. As a result, I had to extract the frames from the GIF instead and had to convert them into a video. While I could do this with any of many online services I specifically needed a synchronised playback as the timing of the content needed to match. The code above does exactly these frame extractions and pairs up nicely with another utility, the img2vid (which converts image files to a video with a choosable frame rate.
Simply set the option to save the frames and then run the img2vid on the single images to make the video and you can use it with controls in your presentation software, be it PowerPoint, or anything else.
The above main part gets you an example GIF (it had to be a cat, right?) and shows you the first frame. Enjoy!
This little script replaces certain properties in an SVG. By default, it only looks first at the file you pass in. Be aware that the wrong replacement can break your SVG. For this reason, the script makes a new SVG by default. As always, the GitHub gist should be the up-to-date version.
Python
#!/usr/bin/env python3# -*- coding: utf-8 -*-# ********** Careful, you may break SVG graphics with this************# ********************** READ THE BELOW FIRST ************************# ********************** No warranty is taken ************************# By default nothing other than finding RGB codes in the SVG is done# and only if you want to change something you can change what you want# to change (inprop) to what it should be (outprop). For this to work# set inspect to False.defsvg_property_replacer(file, path='',inspect='rgb',inprop='rgb(0%,0%,0%)',outprop='rgb(100%,0%,0%)',outfile='',force=False):import osifnot outfile: outfile = file[:-4]+'_replaced.svg'# does the file even exist?ifnot os.path.exists(path+file):# answer no, it doesn't, report it, return Falseprint('File does not exist')returnFalseelifnot (path+file).endswith('.svg'):# answer yes, it does, but isn't an svg, report Falseprint('File is not an SVG')returnFalseelse:# yes the file exists# read the file inwithopen(path+file) as fo: img = [line for line in fo.readlines()]if'svg'notin img[0] and'svg'notin img[1]:# it seemed like a svg, but is not a proper one, this may be# a mistake by the program that produced it in the first placeprint('Warning! No SVG tag has been found at the start of', file)print('For safety reasons only inspection is done.','Set force to override.')print('First lines were', img[0], img[1])ifnot force: inspect ='svg'if inspect:# look for the inspect string in the lines and print them to stdout found =0for _ in img:if inspect in _:print(inspect+_.split(inspect)[1].split(';')[0]) found =1return foundelse:# look for the inprop string in the lines and replace with outpropfor _ inrange(len(img)): img[_] = img[_].replace(inprop, outprop)# write the outfile as _replacedwithopen(path+outfile, 'w') as fo: fo.writelines(img)return outfileif__name__=='__main__':###### EXAMPLE ###### # This example turns the SVG into "darkmode", but be careful# the results may vary, depending on the original file, i.e. if there is # some text in black it'll be white and that may not always make sense# the same for big white areas. Just try it out path ='~' file ='test.svg' file = path+file props = [['rgb(0%,0%,0%)','REPLACEMEAGAIN'], ['rgb(100%,100%,100%)', 'rgb(0%,0%,0%)'], ['REPLACEMEAGAIN', 'rgb(100%,100%,100%)'], ['<svg ', '<svg style="background-color: rgb(15%,15%,15%);" '], ]# file will be named the same with appended _dark outfile = file.split('.svg') outfile = outfile[0] +'_dark.svg'for inprop, outprop in props:# make another file first, so we can try out different thingsif [inprop,outprop] == props[0]: infile = fileelse:# then overwrite the same file always to just have one infile = outfile svg_property_replacer(infile,outfile=outfile,inprop=inprop,outprop=outprop,inspect=False, )
Background & motivation
Say you have an SVG, either made by yourself, from a colleague or by extracting from a PDF. This is a great starting point and editing vector graphics is often far more comfortable than raster graphics as you won’t have to edit single pixels. Now you could edit this file in Inkscape, illustrator, or any of the many other software solutions. But if all you want to do is change a certain color, or remove some part of the graphics, you can do that without installing any other software. Instead, you can open the SVG file with your text editor of choice and search for the colour you want to replace (note that colours in SVG files are generally in the hexadecimal form, i.e. #RRGGBB, a search for “colour picker” will generally help you figure out what to look for/pick as replacement). It might be a good idea to back up your file beforehand as well. So let’s say you have the following rectangle in your SVG:
This will be a bit transparent, white filled with a black solid border (I added another rectangle just for show):
You can first search for “fill:” or for “stroke:” to see the occurrences of colour uses in your file and in other places. As you can see, it can also be useful and simple to change the opacity or similar by simply editing the file and changing that one value, for example, the red to light blue (replacing #ff0000 with #3399ff):
But most likely you want to do more/change more than one occurrence and/or more than one property. This is where the above script comes in, as you can run it like the example at the bottom of the script and change many properties in a row (note that the REPLACEME is so that we don’t just change everything from white to black and then both previous ones back to black.
Use the below Python snippet to create an mp4/webm video based on images in a path that all have a prefix (which can be an empty string too of course). It requires you to have setup ffmpeg to be found on the command line (there would be ways to use the Python version too but this way you can also simply create a link to the standalone version if you are on *nix). The gist version on my github should always be up to date.
Python
# -*- coding: utf-8 -*-"""At some point in time@author: elbarto"""defimg2vid(path,prefix,moviename='auto',movietype='mp4',outrate=15,inrate=15,imgtype='auto',width=1280,height=960,preset='fast',quiet=True, )""" Create a movie (mp4 or webm) from a series of images from a folder. Parameters ---------- path : str Where the images are located. prefix : str The prefix the images have, e.g., img_XX.png moviename : str The name of the movie that should be written out e.g., img_XX.png The default is movie_XX.mp4 where XX is checked avoid overwriting. movietype : str The format of the movie to be created e.g., mp4 or webm The default is mp4, see also parameter moviename. outrate : int, optional The framerate of the input. The default is 15. inrate : int, optional The framerate of the output video. The default is 15. imgtype : str, optional The imagetype to use as input. The default is 'auto', which means that jpg, jpeg, png, gif are looked at and collected width : int, optional The width of the output video. The default is 1280. height : int, optional The height of the output video. The default is 960. preset : str, optional The preset for video creation, determining the creation speed. The default is 'fast', other options are very_fast, medium, slow... quiet : bool, optional Whether to print progress to stdout or not. The default is True. Returns ------- None. """import osimport subprocess# cheap implementation of natsort to avoid dependencydefnatsorted(listlike):import re convert =lambdax: int(x) if x.isdigit() else x.lower() alphanum_key =lambdakey: [convert(c) for c in re.split('([0-9]+)', key)]returnsorted(listlike, key=alphanum_key)# for convenience move to the path where the images are located# will change at the end to the original path again curdir = os.path.abspath(os.curdir) os.chdir(path) filelist = []for entry in os.scandir(path):if (not entry.name.startswith('.')and entry.is_file()and entry.name.startswith(prefix)):passelse:continueif imgtype =='auto': imgtypes = ['png', 'jpeg', 'jpg', 'gif'] chk = [entry.name.lower().endswith(_) for _ in imgtypes]ifmax(chk): filelist.append(entry.name) _imgtype = [_for _ in imgtypesif entry.name.lower().endswith(_)]else:if entry.name.lower().endswith(imgtype): filelist.append(entry.name) filelist = natsorted(filelist)if imgtype =='auto':iflen(_imgtype) !=1:print('Issues with autodetection of image format.','We found the formats', _imgtype,'Please pass in type directly via imgtype=...')returnFalse imgtype = _imgtype[0]if filelist == []:print('No files found with these parameters')else:ifnot imgtype.startswith('.'): imgtype ='.'+ imgtype cmd ="ffmpeg -r " cmd +=f'{inrate} ' cmd +=" -f concat " tmpfile ='temp_filelist.txt'withopen(path + tmpfile, 'w') as fo:for file in filelist: fo.writelines('file '+ (file).replace('/', "\\") +'\n') cmd +=f' -i {tmpfile}' cmd +=' -vcodec libx264' cmd +=f' -preset {preset} ' cmd +='-pix_fmt yuv420p -r ' cmd +=str(outrate) cmd +=' -y -s '+f'{width}x{height} '# may be an issue if you have 1382195208752376502350 movie files in# the same folder which we hope is unlikely! startnumber =0while os.path.exists(path+f'movie_{startnumber}.mp4'): startnumber +=1if moviename =='auto': moviename = (f'movie_{startnumber}.{movietype}').replace('/', os.sep) cmd += movienametry:ifnot quiet:print('Calling', cmd) subprocess.check_call(cmd.split())print(f'Successfully made movie {path+os.sep + moviename}')except subprocess.CalledProcessError:print('Calling ffmpeg failed!','Make sure it is installed on your system via conda/pip/...')finally:pass os.chdir(curdir) os.remove(tmpfile)return path + os.sep + moviename
Background & motivation
Who doesn’t know it? You have to give a talk, illustrate your findings or simply want to show something extra on your poster at a conference with a tablet or linked via QR code. Now you can upload your image sequence to many online pages that will convert it into a format of your choice. After you made the video, you notice a mistake in the images and you have to redo it – maybe more than once even. If you want several videos, repeat the process even more often.
Instead, you could use video software suites that render the images into videos, but this is essentially the same tedious process and often requires you to learn the software (which has its own merit but maybe you are lacking the time). Why not program it instead?
The requirements are actually quite easy to meet, especially if we are using ffmpeg and Python. This requires you to have setup ffmpeg so it can be found on the command line.
Development process
To simplify the process, let’s look at the requirements for the function that were important for me at the time:
Call ffmpeg on the command line
Name the movie and do not overwrite existing movies
Pass in a path of images or a list of files (handy if you store the output from another script)
Which kind of move to make (mp4 usually is compatible the most, but webm is also useful when making videos for the web/browsers – I tend to go with mp4 for powerpoint presentations, but webm is also supported by MS Office 365 nowadays)
How fast the movie should play (in/outrate)
Which image type the images are (read jpeg, jpg, png gif are fine)
The dimensions the video should have (width, height), per default the first image dimension is taken
How the rendering by ffmpeg should be done (fast is usually good enough quality, there is a tradeoff, see documentation of ffmpeg)
Whether to report some progress during the making – aka the quiet option
Some things to consider are:
You could use natsorted, to get a natural sort of the files as that is usually how we humans would sort them. Usually, this makes little difference but natural sorting works better with mixed naming conventions (0001, 0010, 0100 … vs 1, 10, 100 …). Instead of another dependency, a cheap natsort is implemented as well. Replace the function if you actually have natsort installed and want to use it instead.
Instead you can also directly run the video command via ffmpeg on the command line – this is just a thin wrapper to keep some default options in place that made sense to me. You could also write files out to a file and load them via ffmpeg instead …
Other than that, the process is straightforward. Pass in your directory and the prefix that the images might have (tune some things if you want to). Otherwise, enjoy your video making and as a teaser, the following timelapse is made via the above script on a regular basis and linked here
Pass in either Latitude/Longitude to wgs84_to_ch1903 (which by default converts to CH1903+) or “Rechtswert” (x) and “Hochwert” (y) to ch1903_to_wgs84 (which detects if its CH1903+ based on the length/value of the passed digits. The most recent version is available as a github gist from me.
Python
import numpy as npdefdeci2sexa(angle): angle = np.asarray(angle)# Extract DMS degrees = angle.astype(int) minutes = (angle-degrees*60).astype(int) seconds = (((angle-degrees)*60)-minutes)*60# Result sexagesimal secondsreturn seconds + minutes *60.0+ degrees *3600.0defwgs84_to_ch1903(lat, lon, plus=True): lat, lon = deci2sexa(lat), deci2sexa(lon)# Auxiliary values (% Bern) lat_aux = (lat -169028.66) /10000 lng_aux = (lon -26782.5) /10000 x = (200147.07+308807.95* lat_aux +3745.25* np.power(lng_aux, 2) +76.63* np.power(lat_aux, 2) -194.56* np.power(lng_aux, 2) * lat_aux +119.79* np.power(lat_aux, 3)) y = (600072.37+211455.93* lng_aux -10938.51* lng_aux * lat_aux -0.36* lng_aux * np.power(lat_aux, 2) -44.54* np.power(lng_aux, 3))if plus: x +=1000000 y +=2000000return x, ydefch1903_to_wgs84(x, y, plus='auto'):if plus =='auto':if np.nanmax(x) >1200000or np.nanmax(y) >2600000: plus =Trueelse: plus =False# Auxiliary values (% Bern) y_aux = (y -600000)/1000000# would be 2200000 for ch1903plus x_aux = (x -200000)/1000000# would be 1200000 for ch1903plusif plus: x_aux -=1# new ch1903plus system has another digit to distinguish it y_aux -=2# new ch1903plus system has another digit to distinguish it# Process lat lat = (16.9023892+3.238272* x_aux -0.270978* np.power(y_aux, 2) -0.002528* np.power(x_aux, 2) -0.0447* np.power(y_aux, 2) * x_aux -0.0140* np.power(x_aux, 3))# Process lng lon = (2.6779094+4.728982* y_aux +0.791484* y_aux * x_aux +0.1306* y_aux * np.power(x_aux, 2) -0.0436* np.power(y_aux, 3))# Unit 10000" to 1 " and converts seconds to degrees (dec) lon = lon *100/36 lat = lat *100/36return lat, lon
Quite often I find myself having to convert WGS84 to CH1903 coordinate systems and vice versa. Sometimes I even got neither and simply have a center point and some distance (looking at you ground-based remote sensing data). While swisstopo used to have (in 2017 or so) a library to download, the current easiest way is to actually use the github repo from Valentin Minder which contains converter for several programming languages.
However, the repo contains classes (which are great of course) but I often prefer a direct function (which in Python is also a class, but well …). As such, I used the same formulas you can find elsewhere from swisstopo to do the calculation. Since I usually do not care that much about the altitude in these cases there is no option (as of yet) to include it. One upside of this version of the conversion is that its array enabled, i.e. the respective coordinates can be either a single scalar or a numpy array (not a list though ;-)).
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""Created on Wed Sep 15 09:22:30 2021@author: spirrobe"""import osimport datetimeimport requestsimport jsonclasschm15ksession(requests.Session):""" A class for interacting with the CHM-15k data server. This class inherits from the requests.Session class and is designed to facilitate downloading netCDF and zipped netCDF files from the CHM-15k. To use this class, you must have a valid password for accessing the server. Parameters ---------- url : str The URL of the CHM-15k ceilometer. Can be local ip or http URl password : str, optional The password for accessing the CHM-15k. Default is "15k-Nimbus". outpath : str, optional The path to save downloaded files to. Default is the current directory. download2subdirs : bool, optional Whether to put files into a subdirectory as outpath/{year}/{month}/{day} where year, month, day are inferred for each file based on the filename quiet : bool, optional Whether to print information about the download progress. Default is True. Attributes ---------- url : str The URL of the CHM-15k. session : requests.Session The requests session object used to communicate with the server. password : str The password for accessing the CHM-15k data server. outpath : str The path to save downloaded files to. filecount : bool The number of files available on the server. quiet : bool Whether to print information about the download progress. sessionid : str The ID of the current session with the server. zipfiles : list of str The names of the zipped netCDF files available on the server. zipsizes : list of int The sizes of the zipped netCDF files available on the server, in bytes. ncfiles : list of str The names of the netCDF files available on the server. ncsizes : list of int The sizes of the netCDF files available on the server, in bytes. Methods ------- connect() Connects to the CHM-15k data server and establishes a session. getfilelist() Returns a dictionary of available netCDF and zipped netCDF files on the CHM-15k data server. getncfiles(overwrite=False) Downloads all available netCDF files from the CHM-15k to the local file system. getzipfiles(overwrite=False) Downloads all available zipped netCDF files from the CHM-15k to the local file system. """def__init__(self,url,password="15k-Nimbus",outpath='./',download2subdirs=False,timeout=20,quiet=True,*args, **kwargs, ):""" Initialize a new instance of the chm15ksession class. Parameters ---------- url : str The URL of the CHM-15k. password : str, optional The password for accessing the CHM-15k data server. Default is "15k-Nimbus". outpath : str, optional The path to save downloaded files to. Default is the current directory. timeout : bool, optional The timeout in seconds for the get calls, adjust if on low bandwidth/slow network. quiet : bool, optional Whether to print information about the download progress. Default is True. """super().__init__(*args, **kwargs)# assert url, str, 'url must be a str'self.timeout = timeoutself.url = urlifnotself.url.endswith('/'):self.url +='/'ifnotself.url.startswith('http'):self.url ='http://'+self.urlself.__cgi ="cgi-bin/chm-cgi"self.__cgiurl =self.url +self.__cgi#self.session = requests.Session()#self = requests.Session()self.password = passwordself.outpath = outpathself.__subpath =''self.download2subdirs = download2subdirsifnotself.outpath.endswith(os.sep):self.outpath += os.sepself.filecount =Noneself.sessionid =Noneself.zipfiles = []self.zipsizes = []self.ncfiles = []self.ncsizes = []self.quiet = quietdef_filename2date(self, filename):# pattern is YYYYMMDD _ = filename.split(os.sep)[-1].split('_')[0]iflen(_) ==8:# typical netcdf filesreturn _[:4], _[4:4+2], _[4+2:4+2+2]eliflen(_) ==6:# zipfiles do not have a day as they are for the monthreturn _[:4], _[4:4+2]else:print(f'Date could not be inferred from {filename}')return'', '', ''def_filename2datefolder(self, filename): date =self._filename2date(filename)if date[0]: date = [s + i for s, i inzip(['Y','M','D'], date)] date = os.sep.join(date) + os.sepifnotself.outpath.endswith(os.sep): date = os.sep + datereturn dateelse:return''defconnect(self):""" Connect to the CHM-15k using the provided password. This method sends a validation request to the CHM-15k data server with the provided passwordand obtains a session ID that can be used for subsequent requests. Raises ------ requests.exceptions.RequestException If the request fails. """ validationurl =self.__cgiurl+f"?validatetoken&code={self.password}"# this url could be used to check if the connection worked# checkurl = self.__cgiurl+"?checkvalidation"try: resp =self.get(validationurl, timeout=self.timeout)except requests.exceptions.RequestException: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Connection failed, check url {self.url} and 'f'password {self.password}')return sessionid = resp.text.strip().split('{')[1].split('}')[0] resp.close() sessionid = sessionid.split(':')[1].split(',')[0]self.sessionid = sessionidself.cookies.set("session", self.sessionid,domain=self.url.split(':')[1][2:])ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Connection successful to {self.url}')self.sessionid =Truedefgetfilelist(self):""" Get a list of files from the CHM-15k. If the connection to the server has not been established, this method will establish a connection. Sets attributes of the object to contain the return values as well. Returns ------- dict A dictionary containing the following keys: - 'zipfiles': A list of the names of zipped netCDF files. - 'netcdffiles': A list of the names of netCDF files. - 'zipsizes': A list of the sizes of zipped netCDF files. - 'ncsizes': A list of the sizes of netCDF files. """ifself.sessionid:passelse:self.connect() resp =self.get(self.__cgiurl +'?filelist', timeout=self.timeout) filelist = resp.text resp.close() filelist = filelist[filelist.index('{'):] filelist = filelist[:-filelist[::-1].index('}')]try: filelist = json.loads(filelist)except json.JSONDecodeError:ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print('{now}: Issue with getting proper filelist, aborting getfilelist and potential callers')returnNoneself.filecount = filelist['count']self.zipfiles = [i[0] for i in filelist["ncfiles"] if'zip'in i[0]]self.zipsizes = [i[1] for i in filelist["ncfiles"] if'zip'in i[0]]self.ncfiles = [i[0] for i in filelist["ncfiles"] if'zip'notin i[0]]self.ncsizes = [i[1] for i in filelist["ncfiles"] if'zip'notin i[0]]ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Found {filelist["count"]} files in total to be checked')print(f'{now}: Found {len(self.ncfiles)} netCDF files')print(f'{now}: Found {len(self.zipfiles)} zipped netCDF files')return {'zipfiles': self.zipfiles, 'netcdffiles': self.ncfiles,'zipsizes': self.zipsizes, 'ncsizes': self.ncsizes}defgetsinglefile(self, filename, overwrite=True):""" Download a single file from the CHM15k to the specified output path. Parameters ---------- filename : str Name of the file to be downloaded. Can be either zip or nc file. overwrite : bool, optional Flag indicating whether to overwrite the file if it already exists in the output path and has the same size. Defaults to True. Returns ------- None If the file is not available on the server or if the file transfer fails. Raises ------ None Notes ----- This method uses the requests library to download the file from the server, and saves it to the output path using the same filename as on the device. """ifself.filecount:passelse:self.getfilelist()if filename notinself.ncfiles or filename inself.zipfiles:print(f'File {filename} not available')returnelse:if filename inself.ncfiles: filesize =self.ncsizes[self.ncfiles.index(filename)]elif filename inself.zipfiles: filesize =self.zipsizes[self.zipfiles.index(filename)]else:print(f'File {filename} not available')returnifself.download2subdirs:self.__subpath =self._filename2datefolder(filename) os.makedirs(self.outpath +self.__subpath, exist_ok=True)# check if the file exists, and if it does has the same size# if so continueif os.path.exists(self.outpath +self.__subpath + filename): fs = os.path.getsize(self.outpath +self.__subpath + filename) //1024if fs == filesize andnot overwrite:ifnotself.quiet:print(f'File {filename} already exists and has the same ''size as the file on the CHM15k. Pass overwrite to','download anyway')return filecontent =self.get(self.__cgiurl+'/'+filename+"?getfile", timeout=self.timeout)# check if the transfer worked in the firstplace, if not continueif filecontent.status_code !=200:ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Filetransfer failed for {filename}')returnwithopen(self.outpath +self.__subpath + filename, 'wb') as fo: fo.write(filecontent.content)ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Successfully downloaded {filename}')self.__subpath =''defgetncfiles(self, overwrite=False):""" Download netCDF files from the CHM-15k to the specified `outpath`. Parameters ---------- overwrite : bool, optional Whether to overwrite existing files with the same name and size in the `outpath`. Default is False. Raises ------ ValueError If `filecount` attribute is False. Notes ----- This method first checks whether the `filecount` attribute is set. If not, it calls the `getfilelist` method to obtain a list of files available for download. Then, for each netCDF file in the list, it checks whether the file already exists in the `outpath` and has the same size as the file. If not, it downloads the file using a GET request and saves it to the `outpath`. """ifself.filecount:passelse:self.getfilelist() dlcount =0for fileno, (filename, filesize) \inenumerate(zip(self.ncfiles, self.ncsizes)):ifself.download2subdirs:self.__subpath =self._filename2datefolder(filename)# check if the file exists, and if it does has the same size# if so continueif os.path.exists(self.outpath +self.__subpath + filename): fs = os.path.getsize(self.outpath +self.__subpath + filename) //1024if fs == filesize andnot overwrite:ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'Not downloading {filename} as it exists and has the same size')print(f'{now}: Progress at ',f'{round((fileno+1)/len(self.ncfiles) *100,1)} %')continueelse: os.makedirs(self.outpath +self.__subpath, exist_ok=True) filecontent =self.get(self.__cgiurl+'/'+filename+"?getfile", timeout=self.timeout)# check if the transfer worked in the firstplace, if not continueif filecontent.status_code !=200:ifnotself.quiet:print(f'Filetransfer failed for {filename}')continuewithopen(self.outpath +self.__subpath + filename, 'wb') as fo: fo.write(filecontent.content)ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Successfully downloaded {filename}, the {dlcount+1} file')print(f'{now}: Progress at 'f'{round((fileno+1)/len(self.ncfiles) *100,1)} %') dlcount +=1 now = datetime.datetime.now(datetime.UTC)print(f'{now}: Downloaded all {dlcount} files that contained new data 'f'to {self.outpath +self.__subpath}')self.__subpath =''defgetzipfiles(self, overwrite=False):""" Download zip files from the CHM-15k to the specified `outpath`. Parameters ---------- overwrite : bool, optional Whether to overwrite existing files with the same name and size in the `outpath`. Default is False. Raises ------ ValueError If `filecount` attribute is False. Notes ----- This method first checks whether the `filecount` attribute is set. If not, it calls the `getfilelist` method to obtain a list of files available for download. Then, for each zip file in the list, it checks whether the file already exists in the `outpath` and has the same size as the file. If not, it downloads the file using a GET request and saves it to the `outpath`. """ifself.filecount:passelse:self.getfilelist() os.makedirs(self.outpath, exist_ok=True)for fileno, (filename, filesize) \inenumerate(zip(self.zipfiles, self.zipsizes)):ifself.download2subdirs:self.__subpath =self._filename2datefolder(filename)# check if the file exists, and if it does has the same size# if so continueif os.path.exists(self.outpath +self.__subpath + filename): fs = os.path.getsize(self.outpath +self.__subpath + filename) //1024if fs == filesize andnot overwrite:ifnotself.quiet:print('File already exists and has 'f'the same size ({filename})')continueelse: os.makedirs(self.outpath +self.__subpath, exist_ok=True) filecontent =self.get(self.__cgiurl+'/'+filename+"?getfile", timeout=self.timeout)# check if the transfer worked in the firstplace, if not continueif filecontent.status_code !=200:ifnotself.quiet:print(f'Filetransfer failed for {filename}')continuewithopen(self.outpath +self.__subpath + filename, 'wb') as fo: fo.write(filecontent.content)ifnotself.quiet: now = datetime.datetime.now(datetime.UTC)print(f'{now}: Successfully downloaded {filename}')print(f'{now}: Progress at 'f'{round((fileno+1)/len(self.zipfiles) *100,1)} %') now = datetime.datetime.now(datetime.UTC)print(f'{now}: Downloaded all {len(self.zipfiles)} available 'f'zip files at {self.outpath +self.__subpath}')self.__subpath =''if__name__=='__main__': url =''# the url to connect to, either http/s or ip directly of the chm15k a = chm15ksession(urloutpath='./',quiet=False)# establish a connection, setting up a session, this wil be done automatically# upon calling other get functions a.connect()# get the available files in case you want to download only one file a.getfilelist()# usually, one is interested only in the netcdf files that are available,# especially in an operational setting where other files have already# been downloaded. # per default, existing files are not downloaded again# a.getncfiles()# zipfiles are created by the device for each month and can be downloaded as well# per default, existing files are not downloaded again# a.getzipfiles()
Background & motivation
The CHM15k offers the choice between serial and ethernet connection to sample data. While serial connections are true and tested, especially with data logger the reality might be that you don’t have one on-site, its serial ports are full or you would need a USB to serial adapter (which can be quite bothersome with Linux machines. We actually do sample a Parsivel2 with our data server at the CLOUDLAB field site which requires frequent self-compiled drivers as we are running Fedora with its frequent kernel updates….
So we choose to go via the web interface of the Lufft CHM15k even though it requires a login. The upside is that checking for missing data is quite straightforward, it can be interactive and if you forward ports to its network correctly you can also sample it from the outside.
For this purpose, I had a look with the browser inspection tool to see what is being done when the password is sent and used the requests session to stay validated. The rest is fairly standard file checking and downloading. The above allows the script to be changed once with the correct URL (can be the IP or similar, including a port of course). Be aware that you should probably (really really) change the password if you make your device world-accessible via port forwarding.
Once that is done you can run the file via a cronjob or task scheduler as many times as you want as only most recent files are downloaded. Alternatively, import the class and check functionalities yourself for downloading single files or similar. Hope this helps someone out there to facilitate sampling via their ceilometer